
Everything is XML, XML is Everywhere
Steven Pemberton, CWI, Amsterdam
Steven Pemberton, CWI, Amsterdam


When you were looking at those photos you weren't asking yourself "I wonder what format those photos are in".
The same is true for films, and music, for instance.
There are reasons for choosing different formats: suitability, storage space, fidelity, tools, authorability, ...
There is no perfect format. (There is no perfect anything actually)
XML is a popular format.
Advantages: toolchain and pipeline available for generic XML processing. You can easily use new formats within the generic framework.
However, for authoring purposes XML is seldom preferred over a notation more directly suited to the purpose.
People prefer the direct
body {color: blue}
to
<rule><simple-selector name="body"/> <block><property name="color" value="blue"/> </block></rule>
if (max<a) then max=a;
to
<statement><if><condition><comparison name="<"><var name="max"><var name="a"></comparison></condition> <then><statement><assign><var name="max"/> <expression><var name="a"/> </expression></assign></statement></then></if> </statement>
Similarly, authoring languages designed to make HTML input easier, such as for Wikipedia, or Markdown do not use a nested SGML/HTML style.
And doesn't RELAX NG have both an XML syntax and a 'compact' syntax?
I'm not putting XML down here. No one would prefer
{
"type" : "div",
"content" : [
{
"type" : "span",
"content" : [
"text"
]
},
text2"
]
}
over
<div><span>text</span>text2</div>
You choose your formats according to your needs.
<a href="http://www.w3.org/TR/1999/xhtml">XHTML</a>
does not surface the real structure of the underlying data.
To make the relevant structure explicit, we should really write something like:
<a><href><method type="href"/> <domain name="org"/><site name="w3"/><sub name="www"/><path><root><sub name="TR"> <sub name="1999"> <sub name="xhtml"> </sub></sub></sub></root></path></href> <text>XHTML</text></a>
People choose formats based on a large number of sometimes conflicting requirements and constraints.
But XML has that lovely toolchain.
How can we resolve this?
Add a step to the XML processing chain.
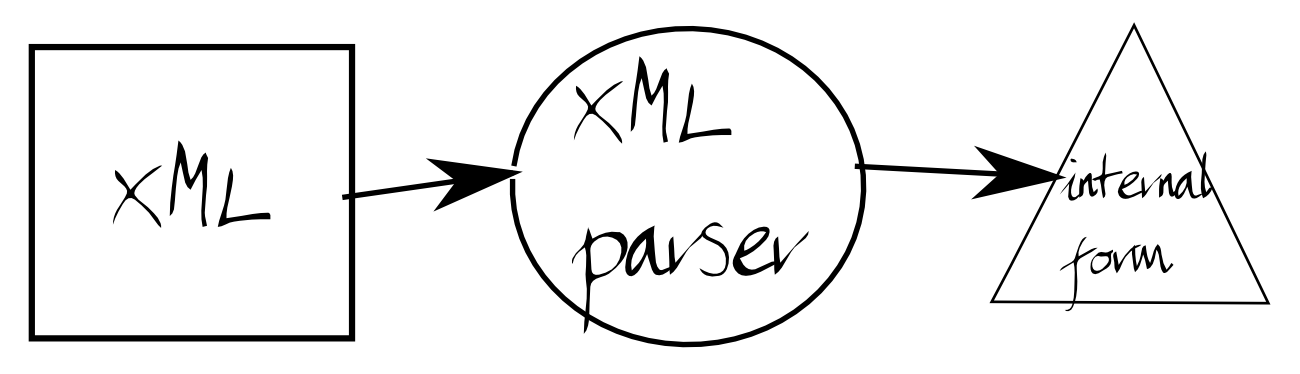
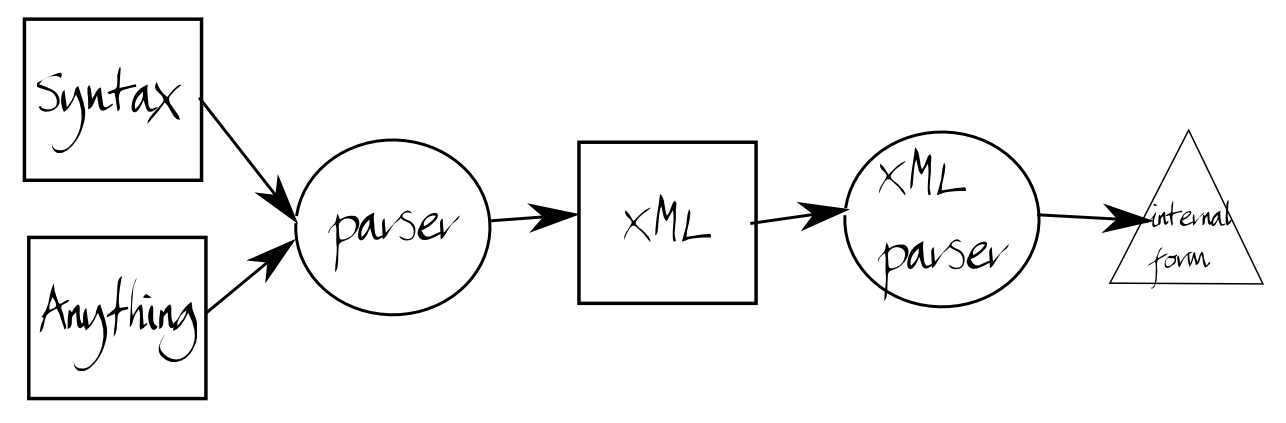
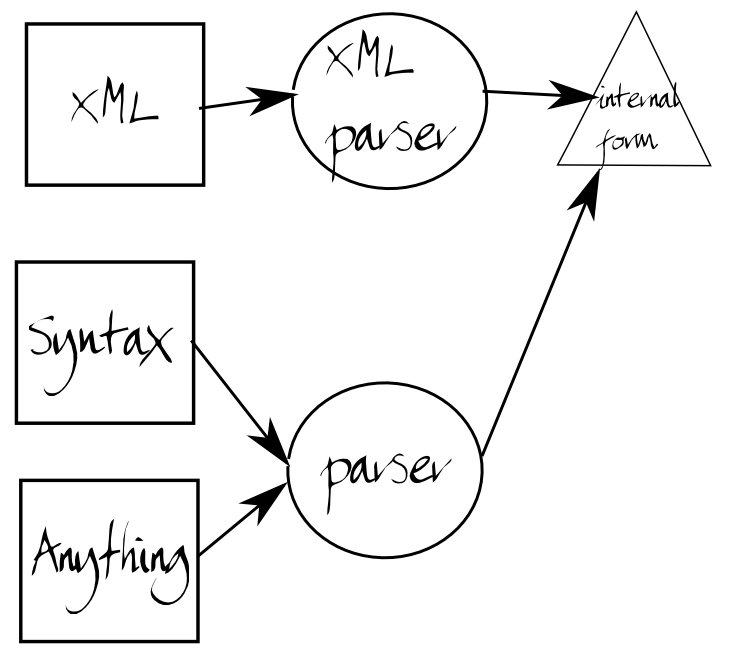
In other words, the input document might be
body {color: blue}
but the result will be the same as if an XML parser had been presented with the XML document
<css>
<rule>
<simple-selector name="body"/>
<block>
<property name="color" value="blue"/>
</block>
</rule>
</css>
We use a variant of VWG format. This looks like:
css: rules.
rules: rule; rules, rule.
rule: selector, block.
block: "{", properties, "}".
properties: property; property, ";", properties.
property: name, ":", value; empty.
selector: name.
name: ...
value: ...
empty: .
(Simplified CSS grammar for the sake of this talk).
body {color: blue}
Parsing this with the grammar gives us:
<css>
<rules>
<rule>
<selector>body</selector>
<block>
<properties>
<property>
<name>color</name>
<value>blue</value>
</property>
</properties>
</block>
</rule>
</rules>
</css>
Terminal symbols such as the brackets, colons and semicolons don't appear in the parse tree. (More later.)
There are certain elements in the tree (rules,
properties) that we really aren't interested in:
<css>
<rules>
<rule>
<selector>body</selector>
<block>
<properties>
<property>
<name>color</name>
<value>blue</value>
</property>
</properties>
</block>
</rule>
</rules>
</css>
The problem becomes even more apparent with a CSS snippet like
body {color: blue; font-weight: bold}
since the <block> element then becomes even more
unwieldly:
<block>
<properties>
<property>
<name>color</name>
<value>blue</value>
</property>
<properties>
<property>
<name>font-weight</name>
<value>bold</value>
</property>
</properties>
</properties>
</block>
<block>
<property>
<name>color</name>
<value>blue</value>
</property>
<property>
<name>font-weight</name>
<value>bold</value>
</property>
</block>
The problem comes from using recursion to deal with repetition. So we use a specific notation for repetition. Zero or more repetitions:
(rule)*
and one or more repetitions:
(rule)+
We extend these postfix operators to also act as infix operators, for a commonly occurring case:
(property)*";" (property)+";"
which respectively mean "zero or more, separated by semicolon" and "one or more, separated by semicolon" (the separator may also be a nonterminal).
Now we can specify our syntax as:
css: (rule)*.
rule: selector, block.
selector: name.
block: "{", (property)*";", "}".
property: name, ":", value; .
name: ...
value: ...
and the parsetree will now look like this:
<css>
<rule>
<selector>body</selector>
<block>
<property>
<name>color</name>
<value>blue</value>
</property>
<property>
<name>font-weight</name>
<value>bold</value>
</property>
</block>
</rule>
</css>
In general, terminal symbols do not appear in the parse-tree.
If you want them to show up, you add an explicit rule for them:
property: name, colon, value; . colon: ":".
which will cause them to show up in the tree like this:
<property>
<name>color</name>
<colon/>
<value>blue</value>
</property>
However, there are places where terminals have semantic meaning, and you do want them to appear in the parse-tree, e.g. the names and values of the properties.
Terminals that are to be copied to the parse tree are marked specially:
name: (+"a"; +"b"; ...etc...; +"9"; +"-")+.
In other words, terminals are discarded, unless they are preceded with a +, when they are copied to the parse-tree.
A refinement is when a syntax rule doesn't represent anything of semantic importance, but there to shorten definitions.
Suppose we wanted to define a series of properties in a separate rule:
properties: (property)*";".
and use it:
block: "{", properties, "}".
but not want <properties> to appear in the final parse
tree.
Rule: If we preceed the use of a rule by a "-", it does not appear in the parse tree:
properties: (property)*";".
block: "{", -properties, "}".
This would result in the same parse-tree as above.
Note that this still allows a rule to be used in other places and appear in the parse tree if needed.
It is only the rule name that doesn't appear in the tree; its content still appears.
For simplicity we have ignored treating spaces in the syntax description. Fixing:
property: name, -colon, value; . colon: -spaces, ":", -spaces. spaces: " "*.
Similarly, we can use it to make empty alternatives more explicit:
property: name, -colon, value; -empty. empty: .
Strictly speaking, this is sufficient.
However, there are possible extensions that give you a little more control over the result.
The most obvious is allowing the specification of attributes. This is simply done by marking the use of rules with at signs:
css: (rule)*.
rule: selector, block.
block: "{", (property)*";", "}".
property: @name, -colon, value.
A rule used like this may clearly not contain any structural elements (though it may contain terminals and refinements), since attributes are not structured, but this is an easy condition to check for.
The parsetree will now look like this:
<css>
<rule>
<selector>body</selector>
<block>
<property name="color">
<value>blue</value>
</property>
<property name="font-weight">
<value>bold</value>
</property>
</block>
</rule>
</css>
If we changed the rule for property to look like this:
property: @name, -colon, @value.
then the resultant parse-tree would look like
<css>
<rule>
<selector>body</selector>
<block>
<property name="color" value="blue"/>
<property name="font-weight" value="bold"/>
</block>
</rule>
</css>
Note that by marking the use of a syntax rule in this way, and not
the definition, it allows the syntax rule to be used for structural elements
(<name>color</name>) as well as for
attributes (name="color").
You could restrict the languages to LL(1) or LR(1) to ensure fast parsing. But:
Parsing algorithms that can parse any context-free grammar are fast enough (e.g. Earley, CYK, or GLR).
The only remaining problem is if the syntax author describes an ambiguous language: so we output one of the parses, and leave it at that.
If expression were defined as:
expr: i;
expr, div, expr.
i: "i".
div: "÷".
then a string such as
i÷i÷i
could be parsed as both
<expr><i/></expr> <div/> <expr> <expr><i/></expr> <div/> <expr><i/></expr> </expr>
and as
<expr> <expr><i/></expr> <div/> <expr><i/></expr> </expr> <div/> <expr><i/></expr>
(i.e as both i÷(i÷i) and (i÷i)÷i ).
To deliver a source document to be parsed, we use a media type that supplies a reference to the required syntax description. For instance:
application/xml-invisible; syntax=http://example.com/syntax/css
Clearly a system can cache well-known syntax descriptions.
It should go without saying that the syntax descriptions themselves are in Invisible XML (though in their case the syntax description must be cached to prevent an infinite loop of processing.)
The definition might look like this:
ixml: (rule)+. rule: @name, -colon, -definition, -stop. definition: (alternative)*-semicolon. alternative: (-term)*-comma. term: -symbol; -repetition. repetition: one-or-more; zero-or-more. one-or-more: -open, -definition, -close, -plus, separator. zero-or-more: -open, -definition, -close, -star, separator. separator: -symbol; -empty. empty: . symbol: -terminal; nonterminal; refinement. terminal: explicit-terminal; implicit-terminal. explicit-terminal: -plus, @string. implicit-terminal: @string. nonterminal: @name. refinement: -minus, @name. attribute: -at, @name.
string: -openquote, (-character)*, -closequote.
name: (-letter)+.
letter: +"a"; +"b"; ...
character: ...
colon: -S, ":", -S.
stop: -S, ".", -S.
semicolon: -S, ";", -S.
comma: -S, ",", -S.
plus: -S, "+", -S.
minus: -S, "-", -S.
star: -S, "*", -S.
open: -S, "(", -S.
close: -S, ")", -S.
at: -S, "@", -S.
openquote: -S, """".
closequote: """", -S.
S: " "*.
This would then parse to the XML form:
<ixml>
<rule name="ixml">
<alternative>
<one-or-more>
<alternative>
<nonterminal name="rule"/>
</alternative><separator/>
</one-or-more>
</alternative>
</rule>
<rule name="rule">
<alternative>
<attribute name="name"/>
<refinement name="definition"/>
</alternative
</rule>
<rule name="definition">
<alternative>
<zero-or-more>
<alternative>
<nonterminal name="alternative"/>
</alternative>
<separator>
<refinement name="semicolon"/>
</separator>
</zero-or-more>
</alternative
</rule>
... etc ...
<rule name="separator">
<alternative>
<refinement name="symbol"/>
</alternative>
<alternative>
<refinement name="empty"/>
</alternative>
</rule>
...
<rule name="colon">
<alternative>
<refinement name="S"/>
<implicit-terminal string=":"/>
<refinement name="S"/>
</alternative>
</rule>
... etc ...
</ixml>
Note in the definition of ixml how many "-"s there are.
Note that we have one mechanism for adding terminals, and a mechanism for removing nonterminals.
Let's instead say that nothing is copied to the syntax tree unless marked with "^" :
ixml: (^rule)+.
rule: @name, colon, definition, stop.
definition: alternative; ^alternative, semicolon, (^alternative)+semicolon.
alternative: (term)*comma.
term: symbol; repetition.
repetition: ^one-or-more; ^zero-or-more.
one-or-more: open, definition, close, plus;
open, definition, close, plus, ^separator.
zero-or-more: open, definition, close, star;
open, definition, close, star, ^separator.
separator: terminal; @nonterminal;
refinement.
symbol: terminal; ^nonterminal; ^refinement.
terminal: ^explicit-terminal; ^implicit-terminal.
explicit-terminal: up, @string.
implicit-terminal: @string.
nonterminal: up, @name.
refinement: @name.
attribute: at, @name.
string: openquote, (character)*, closequote.
name: (letter)+, S
letter: ^"a"; ^"b"; ...
character: ...
colon: ":", S.
stop: ".", S.
semicolon: ";", S.
comma: ",", S.
plus: "+", S.
up: "^", S.
star: "*", S.
open: "(", S.
close: ")", S.
at: "@", S.
openquote: """".
closequote: """", S.
S: " "*.
A remark that should be made is that the design reason for the introduction of the repetition operators "+" and "*" is no longer there. That is, for instance,
ixml: (^rule)+.
could now be written as
ixml: ^rule; ixml, ^rule.
and
alternative: (term)*comma.
could be written
alternative: empty; terms. terms: term; term, comma, terms.
and would give the same output. Nevertheless, the constructs are worth keeping for supporting these often-occurring idioms.
There are obvious extra odds and ends that need adding, such as character ranges, to make terminal specification easier, for instance:
letter: ^"a"-"z"; ^"A"-"Z"; ^"-". S: space*. space: " "; "\t"; "\n".
but these are just details.
You can turn any textual document into an equivalent XML document.
However, it is not in general possible to turn a textual document into a particular XML form without more work.
For instance, you could turn Wikipedia markup into an XML document, but not into XHTML in particular. And
{"a": 1, "b": 2}
can't be transformed into
<j><a>1</a><b>2</b></j>
The input document and the generated XML are (in principle) isomorphic.
Returning the generated XML to its original format is just a process of presentation.
Use XSLT or even CSS in simple cases.
Straightforward to automatically generate the required piece of XSLT directly from the Invisible XML definition.
Alternatively, you could see the syntax definition as a style language for the trees.
For instance, with the earlier example of CSS:
<css>
<rule>
<selector>body</selector>
<block>
<property name="color" value="blue"/>
<property name="font-weight" value="bold"/>
</block>
</rule>
</css>
Displaying this with this bit of CSS:
block:before {content: "{"}
block:after {content:"}"}
property:before {content: attr(name) ":" attr(value) ";"}
will give you
body{color:blue;font-weight:bold;}
Anything that can be parsed can be seen, by looking at it through the right glasses, as a serialisation of XML.
With very simple means, anything that is parsable can be added to the XML ecology.
ADVERT: XForms for CIOs, CEOs and other decision makers, Amsterdam, 22 Nov. See: w3c.nl