About me
Researcher at CWI in Amsterdam (first non-military internet site in Europe -
1988, whole of Europe connected to USA with 64kb link!)
Co-designed the programming language ABC, that was later used as the basis
for Python
At the end of the 80's built a system that you would now call a browser.
Organised 2 workshops at the first Web conference in 1994
Chaired the first style and internationalization workshops at W3C.
Chaired HTML WG for the best part of a decade.
Co-author of HTML4, CSS, XHTML, XML Events, XForms, RDFa, etc
Forms co-chair at W3C
Views
 In the late 80's I was
building with a group an 'application environment'. This system had an
extensible markup language, vector graphics, style sheets, a DOM, client-side
scripting...today you would call it a browser (it didn't use TCP/IP though). It
ran on an Atari ST (amongst others).
In the late 80's I was
building with a group an 'application environment'. This system had an
extensible markup language, vector graphics, style sheets, a DOM, client-side
scripting...today you would call it a browser (it didn't use TCP/IP though). It
ran on an Atari ST (amongst others).
Features
This system had a fairly regular data system, numbers, strings, tuples,
lists, unions etc.
One day when I was explaining the data types to someone, he asked "Why
didn't you use SGML?"
I gave the wrong answer, because I realised later, I hadn't understood the
question.
(Understanding the question is a skill in itself)
No external representations
The point of the Views system was that there were no (standard) external
representations. The name sort of suggests that anyway.
We regarded the internal data as a parse-tree, that could have as many
external representations -- serialisations -- as you liked.
Parsing is easy, and the relationship between serialisation and parsing is
fairly close.
The person asking the question was confusing the internal form with the
(necessary) external form.
Computer scientists
The problem with letting computer scientists design stuff is that we often
lose sight of the correct abstractions. We are so close to the implementation
that we make the mistake of conflating the abstraction with its
implementation.
Example
Let me give an example: the C programming language
C conflates the concept of 'character' with 'unit of storage'. When I was
first learning C, I immediately thought "Abstraction error"!
I am presently still fighting with this abstraction error, trying to upgrade
a program so that it will accept Unicode characters. It is surprisingly hard to
disentangle the conflation.
Character sets
I believe that the current observable confusion between 'character set' and
'character encoding' is attributable at least in part to C's conflation.
It is quite possible that if C (and consequently Unix) hadn't had this
confusion between character and storage unit, that we wouldn't have needed
UTF-8 (although the paucity of metadata in Unix files holds some of the
blame).
Python
Python inherited the same abstraction error from C, again making something
that ought to be really easy (handling all available characters) really
hard.
Only recently has Python finally fixed this.

RGB
RGB is another example of an abstraction error.
Apart from the stupidity of exposing everyday folk to hexadecimal numbers
(an abstraction error in itself), RGB is a description of an implementation of
colours, not a description of colours (a sure sign of an abstraction error).
For instance: yellow is a colour, at a particular frequency. However, there
is no yellow in this slide (there really isn't): what you see is an optical
illusion caused by the way our eyes work. When you play two piano notes you
hear both, but when you 'play' two colours, our eyes think they see a diffent
colour.
Screens do not display yellow, but other devices (printers for instance) do
(printers on the other hand may have no green). A good abstraction for colour
would talk in colours and not in implementations of them. (HSL is an
example).
Programming Languages
Programming languages largely suffer from abstraction errors as well.
1950's
In the 50's, when (so-called) high-level languages first started emerging,
computers cost in the millions. Nearly no one bought computers, nearly everyone
leased them.
When you leased a computer in those days, you would get programmers for free
to go with it. Programmers were essentially free (in comparison with the cost
of the computer).
Nowadays it is exactly the reverse of course. Computers are essentially
free. It is the programmers who are expensive.
The design of programming languages
What this meant was that the computer's time was expensive.
 So a programmer would write the program, copy it to
special paper, give it to a typist, who would type it out, then give the result
to another typist who would then type it out again to verify that it had been
typed correctly the first time.
So a programmer would write the program, copy it to
special paper, give it to a typist, who would type it out, then give the result
to another typist who would then type it out again to verify that it had been
typed correctly the first time.
Why all this extra work? Because it was much cheaper to let 3 people do this
work, than to let the computer discover the errors for you.
The Design of Programming Languages
And so programming languages were designed around the needs of the computer,
not the programmer. It was much cheaper to let the programmer spend lots of
time producing a program than to let the computer do some of the work for
you.
Programming languages were designed so that you can tell the computer what
to do, in its terms, not what you want to achieve in yours.
Almost all present-day programming languages still bear the marks of this
design. They still talk in terms of the computer.
1970's
By the 1970's computers were becoming two orders of magnitude cheaper, and
programmers weren't: the cost of software was starting to hurt.
The DoD did some research and discovered that 90% of the cost of software
production was in debugging.
Interestingly, Fred Brookes in his book "The Mythical Man Month" reported
that the number of bugs in a program is not linear with the length of a program
but quadratic:
b ∝ l1.5
Which means: if a program is ten times as long, it has 30 times as many
bugs, which means it costs 30 times as much to make.
Conversely, a program that is 10 times smaller costs 3% of the larger
program.
The DoD's response
The DoD's response was to organise a competition to design a new programming
language, which became Ada.
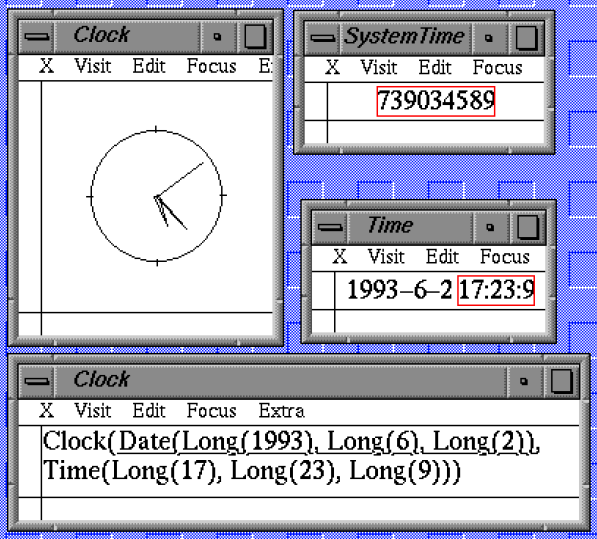
Clock
Here is the essence of the code used for the Views clock example.
type clock = (h, m, s)
displayed as
circled(combined(hhand; mhand; shand; decor))
shand = line(slength) rotated (s × 6)
mhand = line(mlength) rotated (m × 6)
hhand = line(hlength) rotated (h × 30 + m ÷ 2)
decor = ...
slength = ...
...
clock c
c.s = system:seconds mod 60
c.m = (system:seconds div 60) mod 60
c.h = (system:seconds div 3600) mod 24
A clock in C
XForms
XForms originally designed as a replacement for HTML Forms.
- analysis of HTML features
- requirements analysis derived from usage of HTML Forms and other
electronic forms systems.
The first version did roughly that, but thanks to generality in the design
we realised that with small changes it could do much more: you could use it for
applications.
The resultant design
- MVC-based
- intent-based controls
- XML as a first-class data format, both for initialising data from
external sources, as for submission.
Example
What this concretely means is that the data is physically separated from the
controls in the form. The data is placed in the head of the document, and the
controls bind to the data.
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<model xmlns="http://www.w3.org/2002/xforms">
<instance>
<data xmlns="">
<year>2012</year>...
</data>
</instance>
</model>
</head>
<body> ...
Or initialised from external sources
What this concretely means is that the data is physically separated from the
controls in the form. The data is placed in the head of the document, and the
controls bind to the data.
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<model xmlns="http://www.w3.org/2002/xforms">
<instance src="html://www..."/>
</model>
</head>
<body> ...
Controls and initial values
Controls in the body refer to values in the data instance(s) using XPath
expressions:
<input ref="year">...
<input ref="event[1]/title/@language">...
The controls can be initialised by putting values in the data.
Constraints
Relationships between, and restrictions on, values can be specified in the
model, allowing dependent values to be calculated automatically and data
checking to be performed on the client rather than on the server.
<bind nodeset="year" constraint=". > 1752"/>
<bind nodeset="state" required="../country = 'USA'"/>
<bind nodeset="age" calculate="../thisyear - ../birthdate/year"/>
<bind nodeset="birthdate" type="date"/>
Output
Values can be exposed in the document itself, using an output control:
The result for the year <output ref="year"/> is ...
Intent-based Controls
Controls are intent-based, by expressing what the control should do, rather
than how it should look. So a control like this:
<select1 ref="colour">
<label>Colour:</label>
<item><label>red</label>
<value>#ff0000</value></item>
<item><label>green</label>
<value>#00ff00</value></item>
<item><label>blue</label>
<value>#0000ff</value></item>
</select1>
can be represented in different ways depending purely on styling.
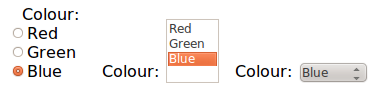
Controls are abstract
Here are three identical controls, just styled differently
(Source)
Initial experience
- Far more powerful and flexible than the HTML Forms it was replacing
- Too slavishly followed the HTML design
Particularly in the use of fixed strings rather than (potentially)
calculated values for such things as the submission URI.
As a consequence this restricted what was possible with the language.
XForms 1.0 → 1.1
As a consequence, XForms 1.1 addressed these shortcomings
The resultant language turned out to be far more than a forms language, but
a declarative application language.
Since XForms has input, output, and a processing engine, XForms is
Turing-complete, and much more than just forms is now possible with the
language.
Experience
Because you specify what you are trying to achieve and not how to achieve
it, there is far less administration to worry about in programs. This means:
shorter programs.
How much shorter?
One correspondent who was converting a large collections of apps for a
company from Javascript to XForms reported that the XForms were about ¼ the
size.
So that means we should expect the production time and cost to reduce by one
eighth, about an order of magnitude. And indeed we do.
Data point: 150 person years becomes 10!
A certain company makes BIG machines (walk in): user interface is very
demanding — traditionally needed 5 years, 30 people.
With XForms this became: 1 year, 10 people.
Do the sums. Assume one person costs 100k a year. Then this has gone from a
15M cost to a 1M cost. They have saved 14 million! (And 4 years)
Data point: A true story
Manager: I want you to come back to me in 2 days with estimates of how long
it will take your teams to make the application
[2 days later]
Javascript man: I'll need 30 days to work out how long it will take to
program it
XForms man: I've already done it.
XForms 1.1 → XForms 2.0
XForms 2.0 (first public working draft) will be published today or
tomorrow.
Biggest changes: XPath 2.0, AVTs
This means: everything in the display is under control of your data. Even
@class.
Another change: accept data in other formats than XML
Data Opacity
- XForms treats its data internally as if it is XML
- XPath both to address data as to calculate new values
- Not the intention that external data be only in XML
- Just as a photo editor doesn't care about the external format, nor does
XForms
- However, since the internal form of the data that XForms deals
with is XML (since the data is accessed using XPath), there has to be a
mapping between the external form and the internal one.
JSON
An obvious data format widely in use on the web is JSON.
There are several mappings defined in both directions between XML and JSON,
but largely because JSON can only represent a subset of what XML can represent,
many of the mappings are cumbersome, and unnatural.
So what we are doing is making a mapping that makes the XPath selectors as
natural as possible.
JSON in XForms
During the design phase we went through several iterations
Key realisation: since the aim is only to address existing JSON stores, it
is not necessary to be able to convert every possible XML representation into
an equivalent JSON representation, only the reverse.
This reduces the task considerably, since it means several features of XML
do not have to be addressed, such as namespaces, attributes, and mixed
content.
Requirements
Some of the requirements for a mapping from JSON to XML for XForms
included:
- All possible JSON values be representable
- Round-trippable, so that you can both read from and submit to a JSON
store.
- As natural-looking selectors as possible.
Opaque data
Ideally, an XForm processing JSON data shouldn't have to know which data
format has been used; so that, for instance, data such as
{"company":"example.com", "locations":[{"city": "Amsterdam"},{"city": "London"}]}
with the right mapping could be selected with XPath selectors like
locations/city[1]
In this way data could be loaded using content negotiation, and will work
whether the data comes in as XML or JSON.
Implementation
Implementation of the mapping is relatively trivial:
At the point where an implementation normally receives a document of type
application/xml (or similar), either during initial instance
initialisation from an external resource, or as the return value of a
submission, if the media type of the resource is
application/json, the resource can be parsed, and
transformed to an equivalent XML instance.
The media type can be recorded as an attribute of the root element, so that
it can be reused if the instance is to be resubmitted as JSON.
Other formats
Clearly this method can be extended to other datatypes such as VCARD and iCalendar. For instance an iCalendar value such
as
BEGIN:VCALENDAR
METHOD:PUBLISH
PRODID:-//Example/ExampleCalendarClient//EN
VERSION:2.0
BEGIN:VEVENT
ORGANIZER:mailto:a@example.com
DTSTART:19970701T200000Z
DTSTAMP:19970611T190000Z
SUMMARY:ST. PAUL SAINTS -VS- DULUTH-SUPERIOR DUKES
UID:0981234-1234234-23@example.com
END:VEVENT
END:VCALENDAR
can be transformed to
<VCALENDAR>
<METHOD>PUBLISH</METHOD>
<PRODID>-//Example/ExampleCalendarClient//EN</PRODID>
<VERSION>2.0</VERSION>
<VEVENT>
<ORGANIZER>mailto:a@example.com</ORGANIZER>
<DTSTART>19970701T200000Z</DTSTART>
<DTSTAMP>19970611T190000Z</DTSTAMP>
<SUMMARY>ST. PAUL SAINTS -VS- DULUTH-SUPERIOR DUKES</SUMMARY>
<UID>0981234-1234234-23@example.com</UID>
</VEVENT>
</VCALENDAR>
Conclusions
XForms has proved its value as an application language.
XForms 2.0 continues its path to more generality.