Steven Pemberton
In a recent radio broadcast about computer technology, the reporter said "your current computer is more powerful than the computer they had on board the first flight to the moon!". While true in itself, what the reporter had been told (and probably couldn't believe) is that your current computer is more powerful than all the computers put together that were used to put a man on the moon. Moore's law [1] is an exponential function, and many people find it hard to get to grips with what such a change means.
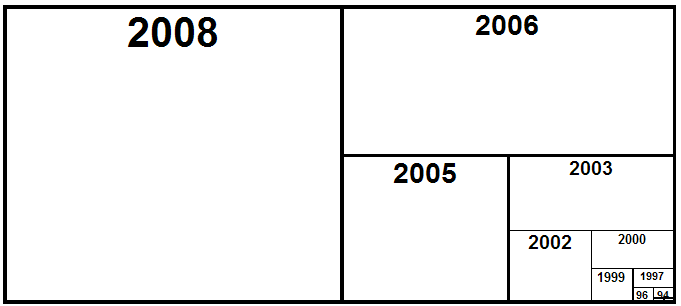
Try this: take a piece of paper and draw a line to divide it into two lengthwise; in one half write this year's date. Now divide the other half into two, a top part and a bottom part, and write the date 18 months ago in the top part.
Now, divide the bottom part into two, left and right, and in the one part write the date 18 months before that (or three years before now). Keep doing this, halving first vertically then horizontally as long as you can, depending on the thickness of your pen.
Moore's Law roughly says that at constant price computers double in speed every 18 months. So if the space with this year's date in it represents the speed of a new computer now, the space with the date 18 months ago represents the speed of a new computer then, and each smaller box represents the speed of a new computer 18 months earlier.
This diagram hopefully demonstrates two things: firstly that your current computer is more powerful than all your earlier computers put together (assuming you don't buy a new computer more often than once per 18 months!), and secondly that when the IBM PC and Macintosh were introduced more than 20 years ago (see that tiny dot?), we had relatively tiny amounts of computer power available. (You might also want to contemplate how much computing power the moon landing actually had available in 1969...)
Of course, if you actually draw the graph of the computers you have owned, you will likely not see an increase that matches Moore's Law. This is because Moore's Law talks about computing power at constant price, and the chances are large that you have taken advantage of Moore's Law to reduce the price you pay for new computers. It has been reported that the median price for desktop computers sold in the U.S. dropped from its peak of $4,500 in 1990 to under $1,500 in 2000 [2]. So your computers while getting faster, haven't been getting as fast as they could have according to Moore's Law since they have also been getting cheaper.
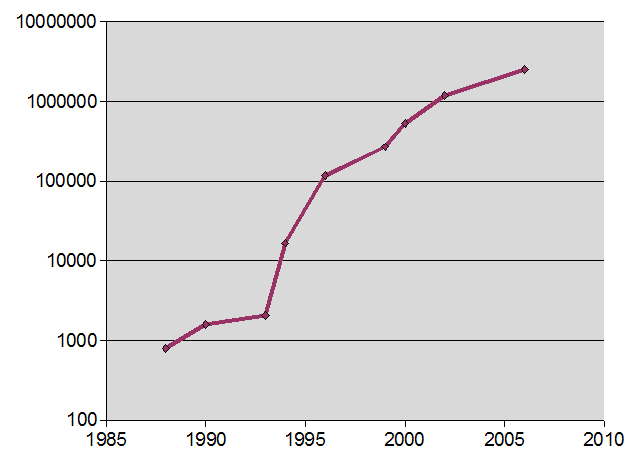
The author's laptop speeds 1988-2006
You can see a similar development with LCD screens which, since each (sub-)pixel is a transistor, are also liable to Moore's Law. Manufacturers have been taking advantage of Moore's Law to lower prices rather than (for the time being) increasing resolution. However, they won't want to drop too low, so since even the lowest specification digital cameras seem to be getting to 10M pixels, we should expect 4000 × 2500 pixel LCD screens in the not-too-distant future.
While Moore's Law is fairly well known, what is less well known is that the same is happening with bandwidth: it is doubling at a fixed rate too, but more like yearly (a recent talk by a top executive at AT&T [3] reported that it is doubling every 10½ months). This law isn't officially called Nielsen's Law, but Jakob Nielsen reported the phenomenon in 1998 [4] and though his doubling rate is of the observed bandwidth increase for the user, rather than the constant price rate, I have retained the name.
It may seem difficult to believe, but when the internet first came to Europe in 1988, the whole continent was connected to the USA with a 64Kbit connection. There was great rejoicing when this was doubled to 128kbit.
As another data point, if you look at the graph of my own home bandwidth recorded over 25 years, noting that the y axis uses a logarithmic scale, you will see a very clear doubling:
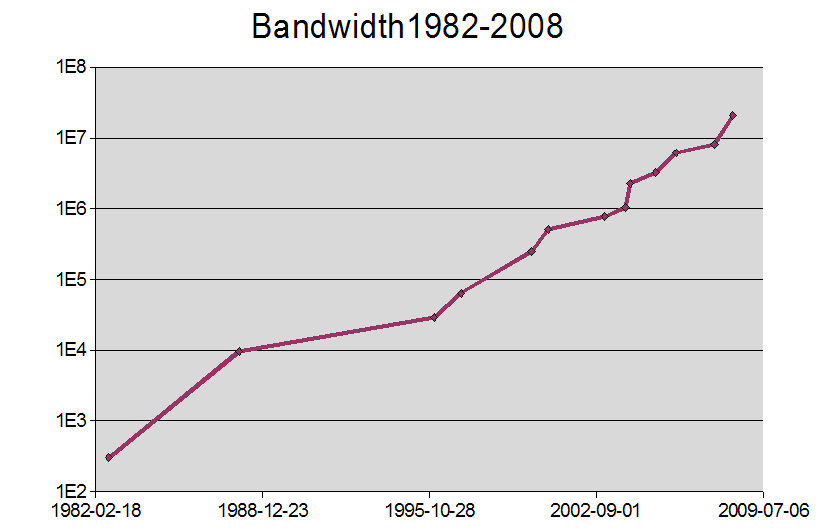 In fact if you
do the maths, you will see that this doesn't represent a doubling per year:
just as with computer power, I have been able to take advantage of the doubling
to reduce my costs, while still enjoying increased bandwidth. But regardless,
what it does mean is that within a decade I should expect to have at least a 1
Gbyte connection to my home.
In fact if you
do the maths, you will see that this doesn't represent a doubling per year:
just as with computer power, I have been able to take advantage of the doubling
to reduce my costs, while still enjoying increased bandwidth. But regardless,
what it does mean is that within a decade I should expect to have at least a 1
Gbyte connection to my home.
Metcalfe's law [5] is actually a hypothesis about the value of any network. It supposes that the value of a network is proportional to the square of the number of nodes in the network:
V(n) = c × n2
Taking this to be true, simple mathematics shows that if we split a network of a given size into two disconnected networks, the total value is halved:
(½n)2 + (½n)2 = ¼n2 + ¼n2 = ½(n2)
This is why it is good that there is only one email network (although it could be argued that SMS is effectively a weak email system), and bad that there are so many Instant Messenger networks. It is why it is good that there is only one World Wide Web.
The term Web 2.0 was invented by a book publisher (O'Reilly) as a term around which to build a series of conferences [6]. It conceptualises the idea of Web sites that gain value by their users adding data to them, such as Wikipedia, Facebook, Flickr, ... Note that the concept existed before the term: Ebay was already Web 2.0 in the era of Web 1.0.
From the point of view of the owner of a Website, this is fantastic of course. Your users do most of the work! And as a consequence Web 2.0 is now big business, with many conferences around the theme.
There is no doubt that Web 2.0 has produced some wonderful websites, but from the point of view of the user there are some dangers, particularly when it comes to information of personal interest: by putting a lot of work into a website, you commit yourself to it, and lock yourself into their data formats too. This is similar to data lock-in when you use a proprietary program. You commit yourself and lock yourself in, and moving comes at great cost.
One of the justifications for creating XML was reducing the possibility of data lock-in, so that even if you chose to move programs, you still had your data in a reasonably accessible form; furthermore having a standard representation for data helps using the same data in different ways too. Now that we have in principle solved the software lock-in problem, we now have to struggle with the website lock-in problem.
Another problem for the user with the Web 2.0 approach is how to decide which site to use. For example, you commit to a particular photo-sharing website, you upload thousands of photos, tag extensively, and then a better site comes along. What do you do? How do you decide which social networking site to join? Do you join several and repeat the work? I am currently being bombarded by emails from networking sites (LinkedIn, Dopplr, Plaxo, Facebook, MySpace, Hyves, Spock, ...) telling me that someone wants to be my friend, or business contact.
How about geneology sites? These are sites that allow you to build up your family tree online, and then look for other trees that contain overlaps, and tell you about them. You choose one and spend months creating your family tree. The site then spots similar people in your tree on other trees, and suggests you get together. But suppose a really important tree for you is on another site.
How about if the site you have chosen closes down: all your work is lost. This has already happened with sites like mp3.com [7] where 250,000 musicians lost their work, and stage6 [8]. How about if your account on a site gets closed down? There is a report of someone whose Google account got hacked, and so the account got closed down [9]. Four years of email lost, no calendar, no Orkut.
There is an account of someone whose Facebook account got closed [10]. Why? Because he was trying to download all the email addresses of his friends into Outlook (using a program, which is disallowed by the conditions of service). Talk about data lock in!
These are all examples of Metcalfe's law. commit to a particular photo-sharing website, you upload Web 2.0 partitions the Web into a number of topical sub-Webs, and locks you in, thereby reducing the value of the network as a whole. This is why you should have a Web Site
What should really happen is that you have a personal Website, with your photos, your family tree, your business details, which aggregators can then turn into added value by finding the links across the whole web. You can still have multiple sites for one topic, such as geneology, but they now have to compete on how well they aggregate; you never have to worry if one dies, or that a better one might come along, or about how to migrate, or about how to get your data out. It is your data, and it stays your data.
So what do we need to realize this? Firstly and principally, machine readable Web pages. When an aggregator comes to your Website, it should be able to see that this page represents (a part of) your family tree, and so on.
One of the technologies that can make this happen has the catchy name of RDFa [11]. You could describe it as a CSS for meaning: it allows you to add a small layer of markup to your page that adds machine-readable semantics. It allows you to say "This is a date", "This is a place", "This is a person", and uniquely identify them on your web page.
Once a page has machine-understandable semantics, you can do lots more with it. If a search engine can derive from the document that the text "the prime minister" means the person we know as Gordon Brown, then a search for "Gordon Brown" can find that page as well, even if it doesn't mention him by name. A browser can offer additional information for something once it knows what it is. Hotel sites no longer have to offer maps of where they are: if they have marked up their address so that the browser knows it is an address, the browser can offer to show you a map. Which map service it offers can be an option you choose. Furthermore, if the browser knows that something is an address, it can offer to add it to your address book. If the browser really knows that something is an announcement for an event like a conference, and can identify the sub-parts, it can offer to add it to your agenda, find it on a map, locate hotels, look up flights, ... This is a win for you, because you know how much trouble it is to organise a trip like that, and you know how many times you have had to enter the start and end dates of a trip as you go to each airline, each hotel site, and so on. This is a win for the browsers because they can have deals with hotel and flight providers. It is a win for the hotel and flight providers because they can reach people who need hotels and flights.
And of course, aggregators can create value by joining data: you can put your family tree on your own website, and family tree aggregators can create websites using it, and still offer the advantages of finding overlaps with other trees, without the disadvantages. You can now, in your personal information, put details of your education, and school-class aggregators can create websites for lost friends.
There is already an approach to semantic data in webpages called microformats [12]. However there are a number of problems with microformats that limit their scalability: the definition of each microformat is centrally defined, it is hard to define your own; each microformat has to be parsed differently, so that the definitions have to be hard-wired in the browser or search engine; nesting of microformats creates problems; microformats can only add semantic information that is about the current page, and not about other pages. RDFa on the other hand allows a thousand flowers to bloom by using a single method to mark up semantic information, that integrates completely into the Semantic Web [13].
So let us call this approach to structured data Web 3.0. If Ebay was Web 2.0 in the era of Web 1.0, can we already see any Web 3.0 in the current era of Web 2.0? Yes, we can see a start. I would argue that Google News already exhibits some of the behaviour we are espousing. The fact that things are news items is identified by their context rather than explicit markup, but an aggregator comes and collects the news, rather than the news creator having to add it themselves to the site. @@
So rather than putting all your data on someone else's website, and the fact that it is there implying a certain semantics, you should put your own data on your own website with explicit semantics. Then you get the true web-effect, with its full Metcalfe value.
But where should you have your Website? Well, it doesn't really matter, because on the whole Websites are interoperable. However, a personal website in most cases doesn't require huge amounts of computing, storage or bandwidth, and what with Moore's Law and Nielsen's Law acting in your favour, your home connection should be more than enough. This is why I believe there is a great future for home network routers that also play the role as servers, such as the Asus WL700GE [14], and the Freecom Storage Gateway FSG-3 [15]. These are wireless routers containing network storage and a media server for in your house, while offering FTP and a world-class Webserver for the outside world. So you can switch off all your home computers, and still serve your webpages to the outside world, with rather low energy use.
[1] Cramming more components onto integrated circuits, by Gordon E. Moore, Electronics, Vol 38, Number 8, April 1965 http://download.intel.com/research/silicon/moorespaper.pdf
[2] The Lives and Death of Moore's Law by Ilkka Tuomi, http://www.firstmonday.org/issues/issue7_11/tuomi/
[3] Impact of the Web on Networks, Devices and Applications, WWW2006, David Belanger
[4] Nielsen's Law of Internet Bandwidth, Jakob Nielsen, http://www.useit.com/alertbox/980405.html
[5] Metcalfe’s Law Recurses Down the Long Tail of Social Networks, By Bob Metcalfe, http://vcmike.wordpress.com/2006/08/18/metcalfe-social-networks/
[6] What Is Web 2.0? Design Patterns and Business Models for the Next Generation of Software by Tim O'Reilly http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.html
[7] MP3.com archive is destroyed, No joy for Robertson By Andrew Orlowski http://www.theregister.co.uk/2003/12/03/mp3_com_archive_is_destroyed/
[8] Stage6 Closes its Doors by David Ficocello http://www.networkingaudiovideo.com/archives/2008/02/stage6_closes_its_doors_today.php
[9] A Google horror story: what happens when you are disappeared Danah Boyd http://www.zephoria.org/thoughts/archives/2008/02/08/a_google_horror.html
[10] Facebook disabled my account Robert Scoble http://scobleizer.com/2008/01/03/ive-been-kicked-off-of-facebook/
[11] RDFa in XHTML: Syntax and Processing, A collection of attributes and processing rules for extending XHTML to support RDF,Ben Adida et al., http://www.w3.org/TR/rdfa-syntax
[12] About microformats http://microformats.org/about/
[13] The Semantic Web A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities, By Tim Berners-Lee, et. al Scientific American, May 2001, http://www.sciam.com/article.cfm?id=the-semantic-web
[14] Asus WL700GE http://www.asus.com/products.aspx?modelmenu=1& model=979&l1=12&l2=43&l3=0
[15] Freecom Storage Gateway FSG-3 http://www.freecom.com/ecProduct_detail.asp?ID=2348