Browser
Researcher at the Dutch national research centre CWI (the first European internet site)
Co-designed ABC, the programming language that Python is based on
In the 80's co-designed what you would now call a browser.
Organised 2 workshops at the first Web conference in 1994
Co-author of CSS, HTML4, XHTML, XML Events, XForms, etc
Chair of HTML and Forms working groups
Until recently, editor-in-Chief of ACM/interactions.
For instance, the tools we use to write text:
HTML is an incredible success, but has also become a sort of Garden of Eden, with lots of Thou Shalt Nots in the form of guidelines
etc, etc, etc
And these communities have all come to the HTML working group to ask for new facilities.
XHTML2 is an attempt by the HTML working group at W3C to produce a simple, unified solution to the problems raised by these diverse communities.
But today I want to focus on the work around data representation.
On: Form – Content – Essence
But also on: Meaning – Diversity – Function
The advantages of keeping presentation and content separated have been largely understood, such as:
CSS Zen Garden demonstrates some of this.



(However, there are some criticisms about what CSS Zen Garden has wrought that I won't go into here)
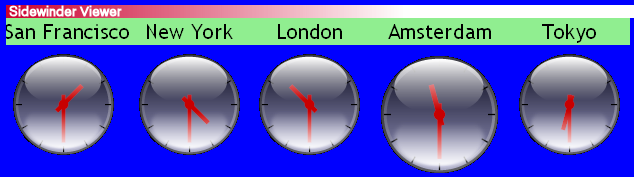
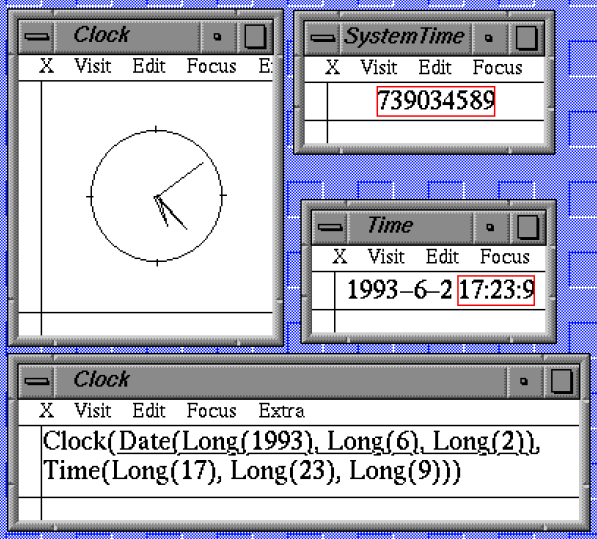
The clocks here in the markup are of the style 11:30:00, and
the SVG stylesheet turns those into the analogue clocks
San Francisco 01:30
New York 04:30
London 10:30
Amsterdam 11:30
Tokyo 18:30
HTML structuring is rather weak.
For instance, one of the biggest problems for non-sighted people with many HTML pages is working out what the structure is. Often the only clue is the level of header used (h1, h2 etc), and often they are not used correctly.
To address this, in XHTML2 you can now make the structure of your documents more explicit, with the <section> and <h> elements.
<section>
<h>A heading</h>
...
<section>
<h>A lower-level heading</h>
...
</section>
</section>
Advantages include:
(h1-h6 are currently still available.)
It is amazing how little issues can take so much effort.
A question that we often had to address was "is <hr> presentational?"
The Japanese community were also asking for a <vr>.
And then we had an aha moment...



These are all <hr>s! <hr> is not presentational, but structural: a lightweight section separator.
The only thing wrong with <hr> is that it is not (necessarily) horizontal, and not (necessarily) a rule!
We already needed a separator element for navigation lists, so we just decided to do away with all the confusion and rename <hr> to <separator>.
A paragraph is now much closer to what people perceive as a paragraph. For instance, this is now allowed:
<p>Advantages include: <ul> <li>easier to cut and paste and keep your heading levels consistent.</li> <li>importing sections in PHP-like situations</li> <li>you are no longer restricted to 6 levels of header.</li> </ul> </p>
... but today is about a high-level view.
When you look at a contract, there is an enormous amount of information that you, as reader, have to plough through.
But the provider or author of the contract may have a very different view of such a contract:
"The standard author's contract applied to author John Smith with a royalty of 10%."
In order to distinguish this from the content of a document as we normally mean, I like to call this the essence of a document.
HTML has next to no support for essence, which is why solutions such as JSP, ASP, and PHP have arisen.
It is also why people have to resort to images to show page counts.
As part of the greatly improved forms facilities of XHTML2, known generically as XForms, it is possible to import data into an XHTML2 document, and expose parts of that data anywhere in the document:
<head>
...
<instance id="author" src="http://..."/>
...
</head>
<body>
... this contract between Example.com ('the publisher')
and <output ref="instance('author')/name"/> ('the author')
...
HTML has structure creating elements, like <p>, headings and <div>, and textual elements, like <strong>, and <span>, and it has a smattering of elements and attributes that essentially add semantics or metadata, such as:
The HTML WG is constantly being asked to add new semantic elements, such as
and it is very hard to decide where to draw the line in adding new elements.
The solution adopted in XHTML2 is not to hard-wire semantics into the language, but to layer meaning in the same way that you layer presentation.
As a result, XHTML2 consists principly of structuring elements, and a layer of semantics.
The semantic layer allows you to give the purpose of an element
<p role="note"> ... <div role="navbar"> ... <section role="news"> ...
and these values are extensible: add any you want.
You can add extra detail to content
It was reported that <span content="2006-09-30">yesterday</span> <span content="Tony Blair">the prime minister</span> flew to Washington ...
You can classify data.
On 1st October at 14:45, Steven Pemberton will give a talk entitled Form – Content – Essence:Designing Markup for Information Representation at The EuroIA 2006 conference.
<p about="#euroia_talk" role="cal:Vevent">
On <span property="cal:dtstart" content="20061001T1245Z">
1st October at 14:45</span>,
<span property="cal:duration" content="PT60M"/>
<span property="cal:dtend" content="20061001T1345Z" />
<span property="dc:creator">Steven Pemberton</span>
will give a talk entitled
<em property="cal:summary">Form – Content – Essence:
Designing Markup for Information Representation</em>
at <span property="cal:location"><em>The EuroIA 2006</em>
conference</span>.
</p>
In a sense, this is Microformats done right.
Once a search engine can derive from the document that the text "the prime minister" means "Tony Blair", then a search for "Tony Blair" can find that page as well, even if it doesn't mention him by name, or a browser might offer additional information, for instance on hovering.
If the browser really knows that something is an address, it can offer to add it to your address book, or find it for you on a map.
If the browser really knows that something is an announcement for an event like a conference, and can identify the sub-parts, it can offer to add it to your agenda, find it on a map, locate hotels, look up flights, ...
But upstream processors can also use the information for other purposes, such as transforming content to different devices.
What happens when you click on a link?
The browser sends the URI to the server, and you get the document back, right?
Wrong: first comes content negotiation. The browser also sends details about preferences, including the languages acceptable.
Which is why it drives me crazy when I go to google.com and get the German language google.de returned, when I've said which languages I can understand, and German isn't among them.
And sites (like bahn.de) which have links to versions in other languages, but doesn't deliver you initially to one in your list of languages.
 The world isn't just PC's
The world isn't just PC's
There are now more browsers on phones than on personal computers.
There are browsers on many new devices: phones, PDAs, printers, even refrigerators; there are increasing numbers of form factors, sizes, resolutions.
Not only do we have diversity of devices, but diversity of users too!
We are all visually impaired at some time or another:
Not only do we have diversity of devices, but diversity of users too!
We are all visually impaired at some time or another:
Most applications do not support accessibility in any meaningful way.
Even if you can zoom the text, the menus and dialogue boxes stay just as
small.
The need for so called ten-foot interfaces is an admission of lack of accessibility.
The accessibility, mobile, and device-independence communities have adopted the semantics parts of XHTML2 with open arms in order to support diversity of content.
XHTML2 supports content negotiation better than HTML.
XHTML2 allows you to mark up media specific sections of the document.
XHTML2 adds XForms.
Although XForms comes from an analysis of the problems with HTML Forms, and addresses those problems, it is in fact much more general than just 'Forms done right'.
In fact since it has input, a data model, a processing model and output, it is suitable for much general-purpose functionality.
As we have already seen, it allows importing data into the document.
It allows dynamic replacement of the data, and so does away with a lot of the need for Javascript for Ajax-style applications.
It allows you to expose and hide parts of the user interface without refreshing the page or resorting to Javascript.
Form controls are abstract and intent-oriented (they say what you are trying to achieve - such as select one from a list- rather than how to achieve it with menus or radio buttons). This means that they are both device-independent and accessible.
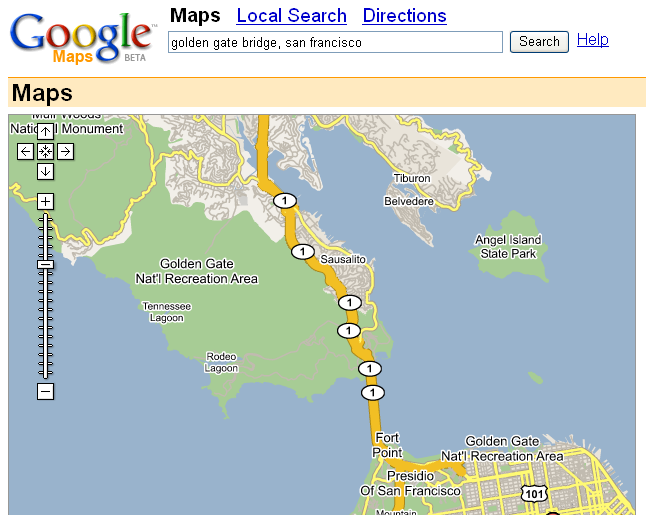 One of the big advantages of applications over the web is that everyone has
always got the most recent version.
One of the big advantages of applications over the web is that everyone has
always got the most recent version.
One of the disadvantages is how difficult they are to author (Google maps is more than 200k of Javascript)
According to the DoD, 90% of the cost of software is debugging.
According to Fred Brookes, in his classic book The Mythical Man Month, the number of bugs increases quadratically according to code size: L1.5.
In other words, a program that is 10 times longer is 32 times harder to write.
Or put another way: a program that is 10 times smaller needs only 3% of the effort.
The problem is, no one writes applications except programmers.
Interesting exception: spreadsheets
Mostly because they use a declarative programming model.
The nice part about declarative programming is that the computer takes care of all the boring fiddly detail.
Some of the most interesting work in this area is being done by xport.net
with their Sidewinder rich web browser.
What they have done is combined XHTML, XForms, SVG and XBL. The SVG is essentially a stylesheet for XHTML+XForms content, being applied using XBL. For instance:
The code says:
<xf:output value="..."
appearance="fp:analogue-clock" class="clock">
The output is then something like 11:30:00, and the SVG turns this into an analogue clock (the XBL keys off the 'appearance' attribute).
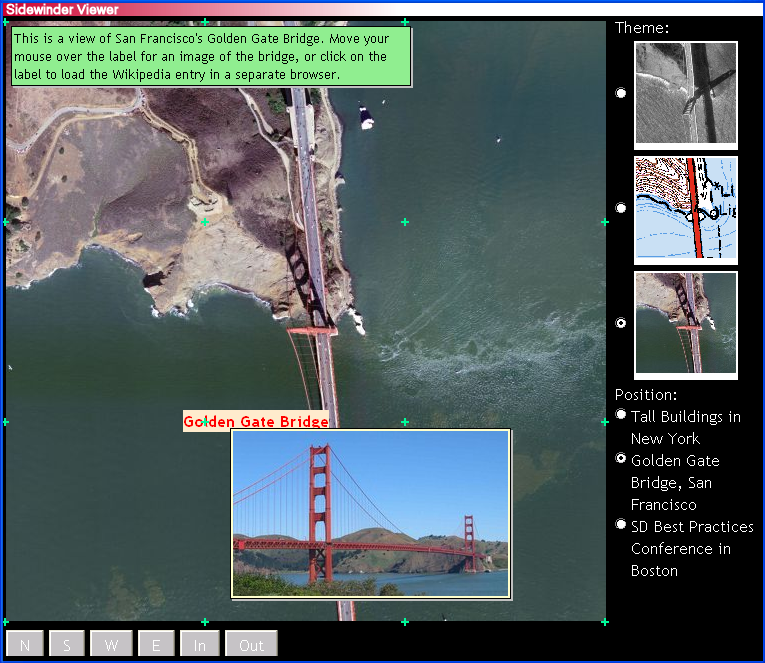
Although the example shown above is not quite complete, it does more than Google maps does and yet it is only 25Kbytes of code (instead of the 200+K of Javascript).
Remember, empirically, a program that is an order of magnitude smaller needs only 3% of the effort to build.
Although the example shown above is not quite complete, it does more than Google maps does and yet it is only 25Kbytes of code (instead of the 200+K of Javascript).
Remember, empirically, a program that is an order of magnitude smaller needs only 3% of the effort to build.
Another data point: a British Insurance company asked two groups to draw up plans to implement certain functionality, and report back the next day:
Although the example shown above is not quite complete, it does more than Google maps does and yet it is only 25Kbytes of code (instead of the 200+K of Javascript).
Remember, empirically, a program that is an order of magnitude smaller needs only 3% of the effort to build.
Another data point: a British Insurance company asked two groups to draw up plans to implement certain functionality, and report back the next day:
Another data point: A major company uses it for designing and implementing user interfaces. It normally takes 30 people 5 years. They recently tried XForms: it took 10 people 1 year.
The advantages of this approach are:
To define a web-format that addresses existing problems and requirements, and will last, needs a lot of work and consultation.
XHTML2 is close to ready now, and will go to last call this year we expect.
XForms is already in widespread use.
Even if XHTML2 is not available in browsers, it is excellent as a content language that can be transformed on the fly. Several large companies are already doing this.
XHTML: http://www.w3.org/MarkUp/
and if you are member company: http://www.w3.org/MarkUp/Group/
and if you aren't, why not? Join here: http://www.w3.org/Consortium/membership
XForms: http://www.w3.org/MarkUp/Forms/
and http://www.w3.org/MarkUp/Forms/2003/xforms-for-html-authors.html
Semantics, see RDFa: http://rdfa.info/