Steven Pemberton, W3C/CWI, Amsterdam, The Netherlands
Researcher at the Dutch national research centre CWI (first European Internet site)
Co-designed the programming language ABC, that was later used as the basis for Python
In the late 80's designed and built a browser, with extensible markup, stylesheets, vector graphics, client-side scripting, etc. Ran on Mac, Unix, Atari ST
Organised 2 workshops at the first Web conference in 1994
Co-author of HTML4, CSS, XHTML, XML Events, XForms, etc
Chair of W3C HTML and Forms working groups
Until recently Editor-in-Chief of ACM/interactions.
But has become a sort of Garden of Eden, with lots of Thou Shalt Nots in the form of guidelines
etc, etc, etc
And these communities have all come to the HTML working group to ask for new facilities.
In designing XHTML2, a number of design aims were kept in mind to help direct the design. These included:
As generic XML as possible: if a facility exists in XML, try to use that rather than duplicating it. This means that it largely already works in existing browsers (main missing functionality XForms and XML Events).
Less presentation, more structure: use stylesheets for defining presentation.
More usability: within the constraints of XML, try to make the language easy to write, and make the resulting documents easy to use.
More accessibility: 'designing for our future selves' – the design should be as inclusive as possible.
Better internationalization.
More device independence: new devices coming online, such as telephones, PDAs, tablets, televisions and so on mean that it is imperative to have a design that allows you to author once and render in different ways on different devices, rather than authoring new versions of the document for each type of device.
Better forms: after a decade of experience, we now know how to make forms a better experience.
Less scripting: achieving functionality through scripting is difficult for the author and restricts the type of user agent you can use to view the document. We have tried to identify current typical usage, and include those usages in markup.
Better semantics: integrate XHTML into the Semantic Web.
Keep old communities happy
Keep new communities happy
Earlier versions of HTML claimed to be backwards compatible with previous versions. For instance, HTML4
<meta name="author" content="Steven Pemberton"> puts the content in an attribute and not in the content of the element for this reason.
In fact, the only version of HTML that is in any sense backwards compatible is XHTML1 (others all added new functionality like forms and tables).
XHTML2 takes advantage of CSS not to be element-wise backwards compatible, but architecturally backwards compatible.
For instance, as mentioned already, much of XHTML2 works already in existing browsers.
XHTML2 is recognisably a family member:
<html xmlns="http://www.w3.org/2002/06/xhtml2/" xml:lang="en">
<head>
<title>Virtual Library</title>
</head>
<body>
<p>Moved to <a href="http://example.org/">example.org</a>.</p>
</body>
</html>
Remove all presentation-oriented elements
Add more structuring elements
Use CSS for all presentation





One of the biggest problems for non-sighted people with many HTML pages is working out what the structure is. Often the only clue is the level of header used (h1, h2 etc), and often they are not used correctly.
To address this, in XHTML2 you can now make the structure of your documents more explicit, with the <section> and <h> elements.
<section>
<h>A heading</h>
...
<section>
<h>A lower-level heading</h>
...
</section>
</section>
Advantages include:
h1-h6 are currently still available.
It is amazing how little issues can take so much effort.
A question that we often had to address was "is <hr> presentational?"
The Japanese community were also asking for a <vr>.
And then we had an aha moment...



These are all <hr>s! <hr> is not presentational, but structural: a lightweight section separator.
The only thing wrong with <hr> is that it is not (necessarily) horizontal, and not (necessarily) a rule!
We already needed a separator element for navigation lists, so we just decided to do away with all the confusion and rename <hr> to <separator>.
A paragraph is now much closer to what people perceive as a paragraph. For instance, this is now allowed:
<p>Advantages include: <ul> <li>easier to cut and paste and keep your heading levels consistent.</li> <li>importing sections in PHP-like situations</li> <li>you are no longer restricted to 6 levels of header.</li> </ul> </p>
You might be surprised to know that <img> was not in the original HTML.
<img> is actually badly designed:
So what we have done is allowed the src attribute on any element. The image replaces the element content, and the element content is fallback. Essentially we have added fallback, moved the longdesc into the document, merged it with alt, and allowed it to be marked up all in one go.
<p src="map.gif">Walk down the steps from the platform turn left, and walk on to the end of the street</p>
The <img> element is still available, but the alt text goes in the content:
<img src="w3c.png">W3C</img>
HTML4 has the 'type' attribute in a number of places as a hint to the browser as to what it could expect if it went and got a resource.
But it is pretty useless. Some browsers ignore it, some don't.
Now it is a specification of the type, and meshes with the HTTP accept: field. This means that
<p src="map" type="image/gif">...
will give you a GIF, or otherwise give you the fallback.
Similarly, you can write:
<p src="map" type="image/png, image/gif">... <p src="map" type="image/*">...
Leaving the type attribute off is equivalent to saying
type="*/*"
In HTML the only method to retain whitespace in content is with
<pre>.
IN XHTML2, all elements can use the attribute
layout="relevant".
<p class="poem" layout="relevant"> ... </p>
This doesn't impose a fixed-width font on the output, just that spaces and newlines are preserved.
<br/> splits a paragraph into different parts, but they are unaddressable with CSS. So instead of a breaking element, XHTML2 uses a structuring element:
<p>Steven Pemberton<br/> CWI/W3C<br/> Amsterdam</p>
is now
<p> <l>Steven Pemberton</l> <l>CWI/W3C</l> <l>Amsterdam</l> </p>
This gives you many more presentational possibilities, such as automatic
numbering of lines, or colouring of alternate lines, etc.
In a non-backwards compatible step, HTML4 allowed any element to become
the target of a link (with id on any element).
XHTML2 extends this by now allowing any element to become the source of a
link as well, by allowing href anywhere.
So, instead of
<li><a href="http://www.w3.org/">W3C</a></li>
you may now write
<li href="http://www.w3.org/">W3C</li>
though <a> is still available.
One thing you see everywhere on the web are menus for navigation, implemented with script.
XHTML2 now supports these natively:
<nl> <label>Go</label> <li href="/">Home</li> <li href="/TR/">Technical reports</li> ... </nl>
Whether they are presented as menus, or in some other way, depends on the platform, the stylesheet, etc.
Certain things that used to be done with elements are now done with attributes: <ins> <del> <bdo>
<p edit="inserted">
and
<span dir="rlo">...
In certain places in HTML4/XHTML1 you can say that an element applies only to a specific media, like:
<style media="print" ...>...
This now applies across XHTML2, to any element.
<p media="screen">This text is only visible on a screen, not on the printed or projected version</p>
Metadata is becoming one of the most important new features of the web. The Semantic Web community has been working for years to integrate metadata properly with XHTML.
Metadata is sprinkled across HTML in lots of places:
etc etc.
XHTML2 creates a unified story about metadata, by relating it to RDF, however without confronting the HTML author with RDF.
RDF is a concept, with several possible external representations (or serialisations, as they are referred to).
Essentially, RDF consists of a collection of facts, or more properly assertions.
Each assertion is about some resource (identified by a URL), and gives a property that that resource has, and a value for that property.
The property is always identified by a URL.
The value of the property may be a URL, a string, or a piece of XML.
(By the way, you can also make assertions about things that haven't got
URLs, in which case they are referred to as blank nodes. For
instance, "There is a person that has an email address of
steven@w3.org", and he is called "Steven Pemberton".)
Unfortunately, the RDF community tends to use terminology that refers to the mechanics of RDF, rather than its purpose.
So they tend to call an assertion a triple, call the thing it is about the subject, the property a predicate, and the value of the property the object.
So be it.
So when we say that the title of this document is "XHTML2 and XForms", and its author is called Steven Pemberton, we say
<http://www.w3.org/2006/...this document...> <http://.../title> "XHTML2 and XForms"
<http://www.w3.org/2006/...this document...> <http://.../creator> "Steven Pemberton"
RDF is the basis for the Semantic Web
It is a very simple, flexible mechanism for representing knowledge.
There are RDF databases and inference engines emerging that can represent the knowledge, and work out conclusions from it.
If a search engine or a browser can work out more about your document than just the text that is in it, searches and other interactions can become better.
For instance, if it can work out that in a page the text "the prime minister" refers to Tony Blair, then a search for Tony Blair could take you to that page, even if it doesn't mention him by name.
If the browser can work out that some text is an address, it can offer to add it to your address book, or find it on a map.
If a browser can work out that some text is for a conference, it could offer to add it to your calendar, or find flights and hotels.
As mentioned, there are several RDF serialisations, such as 'triples' (above), and RDF/XML.
XHTML2 introduces a new representation for RDF assertions by leveraging the existing <meta> and <link> elements of HTML.
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
<ex:fullName>Dave Beckett</ex:fullName>
</rdf:Description>
</ex:editor>
<dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
</rdf:Description>
This says that the document "http://www.w3.org/TR/rdf-syntax-grammar":
<meta about="http://www.w3.org/TR/rdf-syntax-grammar">
<meta property="ex:editor">
<meta property="ex:fullName">Dave Beckett</meta>
<link rel="ex:homePage" href="http://purl.org/net/dajobe/" />
</meta>
<meta property="dc:title">RDF/XML Syntax Specification (Revised)</meta>
</meta>
'about' gives the subject (defaults to the current document)
'property' gives the predicate for a string or XML fragment; the object is in the element content (or the 'content' attribute).
'rel' gives the predicate for a URL: the object is in the href.
The attributes on <meta> and <link> can be used on any element. For instance:
<body>
<h property="title">My Life and Times</h>
...
is a way of saying that "My Life and Times" is both the <title> of this document, as the top-level heading.
You could do the following in HTML already, but now we can extract it as RDF as well:
This work is licensed under the <a rel="dc:rights"
href="http://creativecommons.org/licenses/by/2.0/">
Creative Commons Attribution License</a>.
There is a standard filter called GRDDL for extracting the RDF.
You can explain it using HTML concepts.
If you don't care, you can just ignore it.
It doesn't require you to learn how to use RDF to be able to benefit from it.
The RDF community get their triples without RDF being imposed on the HTML community.
This approach solves a lot of outstanding problems.
For instance, the Internationalisation community needed a way of adding
markup to a title attribute. Now we can just say that
<p title="whatever">
is equivalent to:
<p> <meta property="title">whatever</meta>
And it solves the problem of everyone asking for new elements in XHTML: an element for <navigation>, an element for <note>s (in inline and block versions), an element for lengths, and numbers, and ...
But first a diversion...
The accessibility community needed a way to specify what a particular element was for.
Some examples: that a certain <div> was just a navbar, that another <div> was the main content, etc. So we introduced the 'role' attribute for this. You can now say:
<div role="navigation">...</div> ... <div role="main">...</div>
but once we had that mechanism, it allowed us to add any semantics we wanted, layering it on top of the structure. For example:
<p role="note">...
but also
<span role="note">...
<table role="note">...
role is in a way like class but with meaningful
(semantic) values.
In fact, anyone can add their own role values, so that whole communities can agree on new semantics to overlay on to the content.
Apparently the mobile and device-independent communities (as well as accessibility) are very excited about the possibilities of using role.
In fact, you don't really need RSS anymore:
<h role="rss:title">... <p role="rss:description">...
To go with the role attribute, there is a new way of doing accesskey (which used to be spread through the document). Now in the head you can say things like:
<access targetrole="main" key="M"/>
An advantage of this is that you can have different access keys for different media.
(There is also a targetid for individual elements.)
Events in HTML are very restrictive:
onflash if an event called
flash were introduced.So we invented a new markup for events.
<input type="submit" onclick="validate(); return true;">
is now
<input type="submit">
<handler ev:event="DOMActivate" type="text/javascript">
validate();
</handler>
</input>
We renamed <script> to <handler> because it is sufficiently
different to the HTML <script> to be confusing. In particular
document.write no longer works in XML.
This approach now allows you to specify handlers for different scripting languages:
<input type="submit">
<handler ev:event="DOMActivate" type="text/javascript">
...
</handler>
<handler ev:event="DOMActivate" type="text/vbs">
...
</handler>
</input>
and/or different events:
<input type="submit">
<handler ev:event="DOMActivate" type="text/javascript">
...
</handler>
<handler ev:event="DOMFocusIn" type="text/javascript">
...
</handler>
</input>
HTML Frames created several usability problem that caused several commentators to advise Web site builders to avoid them at all costs. Examples are:
noframes markup is
necessary for user agents that don't support frames. However, almost no
one produces noframes content, and so it ruins Web searches, since search
engines are examples of user agents that do not support frames.XFrames defines a separate XML application, not a part of XHTML2 per se, that allows similar functionality to HTML Frames, with fewer usability problems, principally by making the content of the frameset visible in its URI.
There are already 2 implementations (XSmiles, DENG)
<frames xmlns="http://www.w3.org/2002/06/xframes/">
<head>
<title>Home page</title>
<style type="text/css">
#banner {height: 10em }
#atoz, #nav {width: 20%}
#footer {height: 4em }
</style>
</head>
<group compose="vertical">
<frame id="banner" source="banner.xhtml"/>
<group compose="horizontal">
<frame id="atoz" source="atoz.xhtml"/>
<frame id="main" source="news.xhtml"/>
<frame id="nav" source="nav.xhtml"/>
</group>
<frame id="footer" source="copyright.xhtml"/>
</group>
</frames>
home.xframes#frames(main=a.xhtml,banner=b.xhtml)
The major new functionality in XHTML2 is the forms language, XForms.
After a decade of experience with HTML Forms, we now know more about what we need and how to achieve it.
Soundbite: "Javascript accounts for 90% of our headaches in complex forms, and is extremely brittle and unmaintainable."
XForms has been designed based on an analysis of HTML Forms, what they can do, and what they can't.
There are two parts to the essence of XForms. The first is to separate
what is being returned from how the values are filled in. 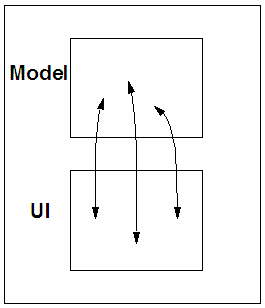
The second part is that the form controls, rather than expressing how they should look (radio buttons, menu, etc), express their intent (this control selects one value from a list).
You then use styling to say how they should be represented, possibly with different styling for different devices (as a menu on a small screen, as radio buttons on a large screen).
Colour: red green blue
XForms gives many advantages over classic HTML Forms:
XForms has been designed to allow much to be checked by the browser, such as
This reduces the need for round trips to the server or for extensive script-based solutions, and improves the user experience by giving immediate feedback on what is being filled in.
Because XForms uses declarative markup to declare properties of values, and to build relationships between values, it is much easier for the author to create complicated, adaptive forms, and doesn't rely on scripting.
An HTML Form converted to XForms looks pretty much the same, but when you start to build forms that HTML wasn't designed for, XForms becomes much simpler.
XForms is properly integrated into XML: it is in XML, the data it collects in the form is XML, it can load external XML documents as initial data, and can submit the results as XML.
By including the user in the XML pipeline, it at last means you can have end-to-end XML, right up to the user's desktop.
However, it still supports 'legacy' servers.
XForms is also a part of XHTML2.
Rather than reinventing the wheel, XForms uses a number of existing XML technologies, such as
This has a dual benefit:
Data can be pre-loaded into a form from external sources.
Existing Schemas can be used.
It integrates with SOAP and XML RPC.
Doesn't require new server infrastructure.
Thanks to the intent-based controls, the same form can be delivered without change to a traditional browser, a PDA, a mobile phone, a voice browser, and even some more exotic emerging clients such as an Instant Messenger.
This greatly eases providing forms to a wide audience, since forms only need to be authored once.
Thanks to using XML, there are no problems with loading and submitting non-Western data.
XForms has been designed so that it will work equally well with accessible technologies (for instance for blind users) and with traditional visual browsers.
XMLDOMCSSJavascriptXHTMLXPathXForms
��� =Regular XHTML Browser
Time to build all of above: 3 programmers, 4 months
Total footprint (on IPAQ implementation): 400K (above Java VM)
In fact this is quite evolutionary: XForms uses existing W3C components. It is only the XForms processing model that describes when to calculate values that is really new.
Open standard
Wide industry support
Widely implemented
No vendor lock-in!
(If you think this is a good idea, join W3C!)
Take this simple HTML form:
<html>
<head><title>Search</title></head>
<body>
<form action="http://example.com/search" method="get">
Find <input type="text" name="q">
<input type="submit" value="Go">
</form>
</body>
</html>
The main difference in XForms is that details of the values collected and
how to submit them are gathered in the head, in an element called
model; only the form controls are put in the body.
So in this case you put the following in the head (XForms elements and attributes are in lower case):
<model>
<instance>
<data xmlns=""><q/></data>
</instance>
<submission
action="http://example.com/search"
method="get"
id="s"/>
</model>
The <form> element is now no longer needed; the
controls in the body look like this:
<input ref="q"><label>Find</label></input>
<submit submission="s">
<label>Go</label>
</submit>
<html http://www.w3.org/2002/06/xhtml2/" xml:lang="en">
<head>
<title>Search</title>
<model>
<instance>
<data xmlns=""><q/></data>
</instance>
<submission
action="http://example.com/search"
method="get" id="s"/>
</model>
</head>
<body>
<p>
<input ref="q"><label>Find</label></input>
<submit submission="s"><label>Go</label></submit>
</p>
</body>
</html>
Although in simple cases the instance element is optional, it
is good practice to include an explicit instance, like this:
<instance>
<data xmlns=""><q/></data>
</instance>
...
<input ref="q">
<label>Search</label>
</input>
ref="q"
that there really is a q in the instance.<data> here, but you can use any tag you
like.For initialising controls including initialising checked boxes, and selected menu items etc., you just supply an instance with pre-filled values. For the search example:
<instance>
<data xmlns=""><q>Keywords</q></data>
</instance>
would pre-fill the text control with the word Keywords.
results to the search form, we
change the instance to:<instance>
<data xmlns="">
<q/>
<results>10</results>
</data>
</instance>
<instance src="http://example.org/templates/t21.xml"/>
<data> <w>640</w> <h>480</h> <d>8</d> </data>
src="file:data.xml"This makes configuring hardware even easier than it now is: instead of the device hosting a web server that can deal with HTML Forms, all it has to do is deliver its configuration parameters as an XML document, and XForms provides the interface.
ref attribute on controls can be any XPath
expression<title> element in an
XHTML document
<input ref="/h:html/h:head/h:title">...
(i.e. the title element within the head
element within the html element, all in the XHTML
namespace)
class attribute on the body element:
<input ref="/h:html/h:body/@class">...
Suppose a shop has very unpredictable opening hours (perhaps it depends on the weather), and they want to have a Web page that people can go to to see if it is open. Suppose the page in question has a single paragraph in the body:
<p>The shop is <strong>closed</strong> today.</p>
Well, rather than teaching the shop staff how to write HTML to update this, we can make a simple form to edit the page instead:
<model>
<instance
src="http://www.example.com/shop.xhtml"/>
<submission
action="http://www.example.com/shop.xhtml"
method="put" id="change"/>
</model>
...
<select1 ref="/h:html/h:body/h:p/h:strong">
<label>The shop is now:</label>
<item><label>Open</label><value>open</value></item>
<item><label>Closed</label><value>closed</value></item>
</select1>
<submit submission="change"><label>OK</label></submit>
XForms has equivalent controls for everything that you can do in HTML.
But there is an important difference: XForms controls are not presentation based, but intent-based – they say what they are meant to achieve not how they do it.
For instance, a select control
<select1 ref="country"> <label>Country</label> <item><label>Netherlands</label><value>nl</value></item> <item><label>United Kingdom</label><value>uk</value></item> <item><label>France</label><value>fr</value></item> </select>
can be represented using radio buttons, a drop-down menu, a select list (or anything else suitable you can think of)
depending on the style-sheet or the choice of the device.
Country Netherlands United Kingdom France
As already said, XForms has equivalents for all HTML controls, such as text, text boxes, selecting one or many, file upload, etc.
A user agent may adapt an input control based on knowledge of the data-type involved.
For instance
<input ref="depart"> <label>Departure date</label> </input>
can pop up a date picker control.
XForms has a couple of extra controls:
<range ref="volume"
start="1" end="10" step="0.5">
may be represented with a slider or similar.
The output control allows you to include values as text in
the document.
Your current total is: <output ref="sum"/>
or
<output ref="sum"><label>Total</label></output>
This can be used to allow the user to preview values being submitted.
You can also calculate values:
Total volume: <output value="height * width * depth"/>
(where height, width and depth are
values collected by other controls.)
These are used to reveal and hide parts of the interface.
<switch>
<case id="inputname">
<input ref="name">...</input>
<trigger>
<label>Next</label>
<toggle case="inputage"
ev:event="DOMActivate" />
</trigger>
</case>
<case id="inputage">
<input ref="age">...</input>
<trigger>...</trigger>
</case>
...
</switch>
An example
Repeat allows you to bind to repeating items in an instance. There are also facilities to delete and insert items in a repeating set.
<expenses>
<item>
<date/><who/><what/><amount/><currency/>
</item>
<item>
<date/><who/><what/><amount/><currency/>
</item>
</expenses>
<repeat ref="expenses/item"> <input ref="date"><label>Date</label></input> ... </repeat>
You have already seen an example
The 'model binding' properties that you can control are:
Note that in XForms it is the collected value that has the property, not the control, but the property shows up on all controls bound to the value.
These properties use a <bind> element that goes in the
<model>. To use bind, you must have an
explicit <instance> element.
To disable controls you use the relevant property. For
instance, to say that the credit card number only needs to be filled in if
the person is paying by credit, you can write:
<model>
<instance><data xmlns="">
<amount/><method/>
<cc>
<number/><expires/>
</cc>
</data></instance>
<bind nodeset="cc"
relevant="../method='credit'"/>
</model>
An example of what we are going to do
<bind nodeset="cc"
relevant="../method='credit'"/>
cc are only relevant
when method has the value credit, and will
therefore be disabled for other values of method.The controls could be written like this (but note that there is no indication that they may get disabled: that is inherited from the value they refer to):
<select1 ref="method">
<label>Method of payment:</label>
<item>
<label>Cash</label><value>cash</value>
</item>
<item>
<label>Credit card</label><value>credit</value>
</item>
</select1>
<input ref="cc/number"><label>Card number:</label></input>
<input ref="cc/expires"><label>Expiry date:</label></input>
Similarly to relevant, you can specify a condition under
which a value is read-only. For instance:
<model>
<instance><data xmlns="">
<variant>basic</variant>
<color>black</color>
</data></instance>
<bind nodeset="color"
readonly="../variant='basic'"/>
</model>
This example says that the default value of color is
black, and can't be changed if variant has the
value basic.
A useful new feature in XForms is the ability to state that a value must be supplied before the form is submitted.
The simplest case is just to say that a value is always required. For instance, with the search example:
<model> <instance><data xmlns=""><q/></data></instance> <bind nodeset="q" required="true()"/> <submission .../> </model>
but like the readonly and relevant attributes,
you can use any XPath expression to make a value conditionally required:
<bind nodeset="state"
required="../country='USA'"/>
which says that the value for state is required when the
value for country is "USA".
It is up to the browser to decide how to tell you that a value is required, but it may also allow you to define it in a stylesheet.
This property allows you to add extra constraints to a value. For instance:
<bind nodeset="year" constraint=". > 1970"/>
constrains the year to be after 1970.
Note the XPath use of "." to mean "this value".
It is possible to indicate that a value in the instance is calculated from other values. For instance:
<bind ref="volume" calculate="../height * ../width * ../depth"/>
When a value is calculated like this, it automatically becomes
readonly.
There are a number of functions available, including:
<bind nodeset="taxrate" calculate="if(../salary > 50000, 50, 33)"/>
<bind nodeset="q" type="xsd:integer"/>
<bind nodeset="homepage" type="xsd:anyURI"/>
There are a number of useful built-in types you can use, including:
select)You can apply Schemas to instances:
<model schema="types.xsd"> ... </model>
or include them inline:
<model>
...
<xsd:schema>
...
</xsd:schema>
...
</model>
If you have several binds referring to the same value, you can combine them:
<bind nodeset="q" type="xsd:integer"
required="true()"/>
Now to look at details of submission, like multiple submissions, submission methods, and what happens after submission.
<model>
<instance><data xmlns=""><q/></data></instance>
<submission id="com"
action="http://example.com/search"
method="get"/>
<submission id="org"
action="http://example.org/search"
method="get"/>
</model>
and then in the body:
<input ref="q"><label>Find:</label></input>
<submit submission="org">
<label>Search example.org</label>
</submit>
<submit submission="com">
<label>Search example.com</label>
</submit>
Find:
method="post"
method="put":<submission
action="file:results.xml"
method="put"/>
which saves your results to the local filestore by using the
file: scheme.
replace on the submission element.replace="instance" replaces only the instancereplace="none" leaves the form document as-is without
replacing it.<model>
<instance><data xmlns="">
<accountnumber/><name/><address/>
</data></instance>
<submission method="get"
action="http://example.com/prefill"
id="prefill" replace="instance"/>
<submission method="put"
action="http://example.com/change"
id="change" replace="none"/>
</model>
...
<input ref="accountnumber"><label>Account Number</label></input>
<submit submission="prefill"><label>Find</label></submit>
<input ref="name"><label>Name</label></input>
<textarea ref="address"><label>Address</label></textarea>
<submit submission="change"><label>Submit</label></submit>
id attribute on each model, and a
model attribute on each control:<model id="search"> <instance><data xmlns=""><q/></data></instance> <submission id="s" .../> </model> <model id="login"> <instance><data xmlns=""><user/><passwd/></data></instance> <submission id="l" .../> </model> ... <input model="search" ref="q"><label>Find</label></input> <submit submission="s"><label>Go</label></submit> ... <input model="login" ref="user"><label>User name</label></input> <secret model="login" ref="passwd"><label>Password</label></input> <submit submission="l"><label>Log in</label></submit>
<model>
<instance id="currencies">
<currencies>
<currency name="USD">125</currency>
...
</instance>
<instance id="costs">
<item>
<date/><amount/><currency/>
...
</item>
</instance>
</model>
...
<input ref="instance('costs')/date">
<label>Date</date>
</input>
<model>
<instance>
<employee xmlns="">
<name/>
<number/>
<salary/>
<taxrate/>
...
</employee>
</instance>
<instance id="tax" src="/finance/taxes"/>
<bind nodeset="taxrate"
calculate="if(../salary > instance('tax')/limit,
instance('tax')/highrate,
instance('tax')/lowrate)"/>
Useful for filling itemsets in select and select1:
<select ref="value">
<label>...</label>
<itemset nodeset="instance(x)">
<label ref="names"/>
<copy ref="values"/>
</itemset>
</select>
or creating dynamic labels (think multilingual) [example]:
<label ref="instance(labels)/label[msg='age']"/>
<label> can also take src="..."
At release XForms had more implementations announced than any other W3C spec had ever had at that stage
Different types of implementation:
Many big players doing implementations, e.g.
As you would expect with a new technology, first adopters are within companies and vertical industries that have control over the software environment used.
That list is there just to give a taste, but amongst others not mentioned there are at least 3 fortune 500 companies who don't want it to be public knowledge so that their competitors don't get wind of it.
As more industries adopt XForms, the expectation is that it will then spread out into horizontal use.
XSmiles now running under J2ME PP




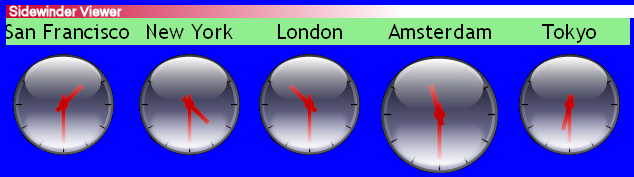
XForms has everything needed for an application:
People are already using XForms for some pretty exciting applications. xport.net who produce FormsPlayer are doing the most interesting stuff, by using SVG as the stylesheet language. They have produced examples such as a world clock, a contacts database, and even Google Maps in XForms!
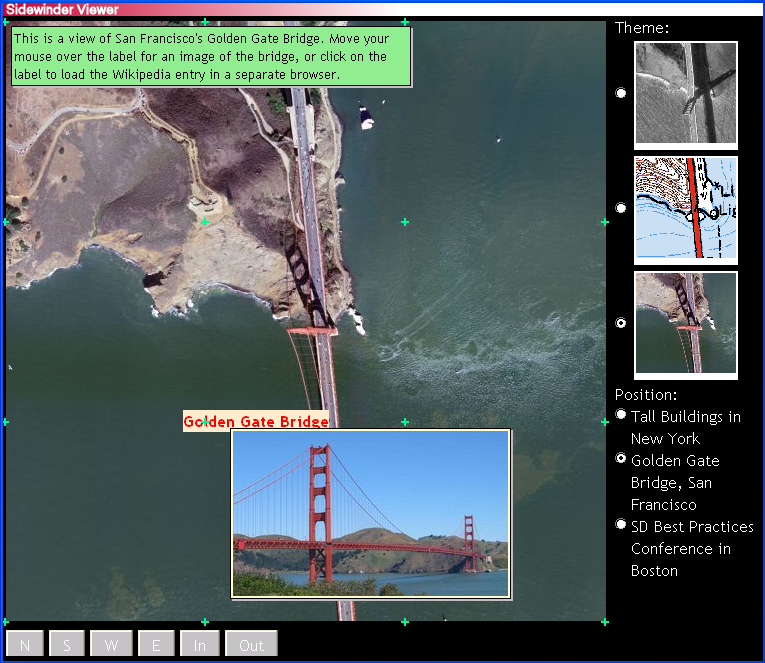
The interesting thing about this last example is that it is 25K of XForms, compared with 200K+ of javascript...
This is largely thanks to the declarative programming model of XForms, that means that you don't have to deal with lots of the fiddly administrative details.
Bear in mind that empirical evidence suggests that a program that is an order of magnitude larger takes 34 times as much effort; or put the other way, a program that is an order of magnitude smaller costs 3% of the effort...
This has been backed up recently by a company using XForms for designing special-purpose interfaces. Usually it takes 30 people 5 years to finish one project. With XForms it took 10 people 1 year (including learning XForms).
XForms is achieving critical mass much faster than we had anticipated. Companies large and small, consortia, even governments and government agencies are beating a path to our door.
Apart from offering a far more managable base for forms on the web, we believe that XForms is an excellent basis for future web applications, because it offers a model that gives you:
XHTML2 has been designed on the basis of requirements from a large number of different communities.
It has been designed to be as recognisably XHTML as possible within the constraints of the new requirements.
It is going to last call shortly: we welcome your comments!
Steven Pemberton: www.cwi.nl/~steven
These slides: well, find 'em!